En un mercado en el que las estadísticas de transmisiones son cada vez más populares, es fundamental optimizar el procesamiento de datos para poder reducir costos y garantizar la calidad y la integridad de datos. Un enfoque consiste en centrarse en trabajar solamente con los datos que cambiaron, en lugar de con todos los que hay disponibles. Aquí es donde sirve la captura de datos de cambio (CDC). La CDC es una técnica que permite este enfoque optimizado.
Los que trabajamos en Dataflow, el servicio de procesamiento de datos en transmisión de Google Cloud, desarrollamos una solución de muestra que permite transferir un flujo de datos cambiados provenientes de cualquier tipo de base de datos MySQL en versiones 5.6 y posteriores (autoadministrada, local, etc.), y sincronizarlo con un conjunto de datos en BigQuery.
Esta solución está disponible dentro del repositorio público de plantillas de Dataflow. Puedes encontrar instrucciones para usar la plantilla en la sección
README del repositorio de GitHub.
La CDC proporciona una representación de los datos que cambiaron en una transmisión, lo que permite que los cálculos y el procesamiento se centren específicamente en los registros cambiados. Se puede aplicar la CDC para muchos casos de uso. Algunos ejemplos incluyen la replicación de una base de datos crítica, la optimización de un trabajo de análisis en tiempo real, la invalidación de la memoria caché, la sincronización entre un almacén de datos transaccionales y otro de tipo almacén, y mucho más.
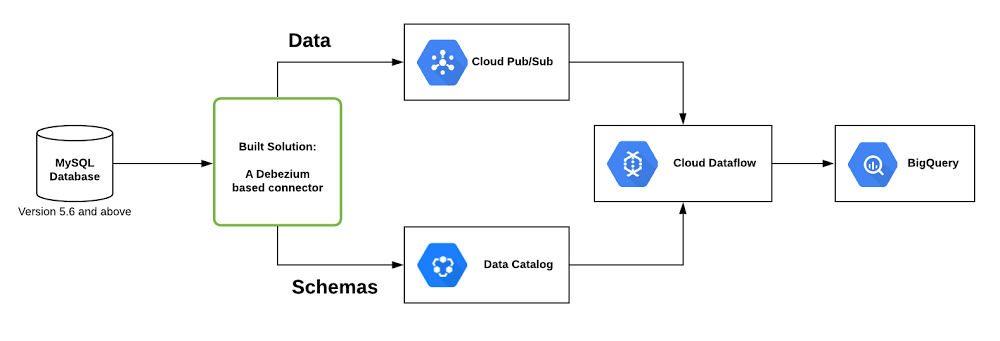
Cómo mueve datos de MySQL a BigQuery la solución de CDC de Dataflow
La solución implementada, que se muestra a continuación, funciona con cualquier base de datos MySQL, la cual se supervisa mediante un conector que desarrollamos basado en Debezium. El conector almacena los metadatos de la tabla utilizando Data Catalog (el servicio de administración de metadatos escalable de Google Cloud) y envía las actualizaciones a Pub/Sub (tecnología de transferencia de transmisiones y mensajería de Google Cloud). Luego, una canalización de datos toma esas actualizaciones de Pub/Sub y sincroniza la base de datos MySQL con un conjunto de datos de BigQuery.
Esta solución se basa en
Debezium, una excelente herramienta de código abierto para la CDC. Hemos desarrollado un conector configurable basado en esta tecnología que puedes ejecutar de forma local o en tu propio entorno de Kubernetes para enviar los datos de los cambios a Pub/Sub.