Dataproc de Google Cloud ofrece a los científicos de datos una forma fácil, escalable y totalmente administrada de analizar datos usando Apache Spark. Se compiló Apache Spark para ofrecer un alto rendimiento, pero los científicos de datos y otros equipos necesitan un nivel de rendimiento incluso más alto, ya que se deben responder más preguntas y predicciones usando conjuntos de datos que están creciendo rápidamente.
Con esto en mente, Dataproc ahora te permite usar
GPU de NVIDIA para acelerar XGBoost, una biblioteca común de software de código abierto, en una canalización de Spark. Esta combinación puede acelerar el desarrollo y el entrenamiento del aprendizaje automático hasta 44 veces, así como reducir los costos 14 veces cuando se utiliza XGBoost. Con este tipo de aceleración de la GPU para XGBoost, puedes obtener un mejor rendimiento, velocidad, precisión y menor TCO, además de una experiencia optimizada a la hora de implementar y entrenar modelos. Poner en funcionamiento clústeres elásticos de Spark y XGBoost en Dataproc demora unos 90 segundos. (Describiremos este proceso con mayor detalle más adelante en la publicación).
La mayoría de las cargas de trabajo del aprendizaje automático (AA) de la actualidad en Spark funcionan con CPU tradicionales, lo que puede ser suficiente para desarrollar aplicaciones y canalizaciones, o trabajar con conjuntos de datos y flujos de trabajo que no son intensivos en términos computacionales. Sin embargo, una vez que los desarrolladores agregan a las aplicaciones y canalizaciones flujos de trabajo intensivos en términos computaciones o componentes de aprendizaje automático, se alargan los tiempos de procesamiento y se necesita más infraestructura. Incluso con clústeres de computación a escala y el procesamiento en paralelo, los tiempos de entrenamiento de los modelos todavía tienen que reducirse drásticamente para acelerar la innovación y las pruebas iterativas.
Este avance hacia la aceleración en la GPU con XGBoost y Spark en Dataproc es un gran paso para facilitar la distribución de extremo a extremo de las canalizaciones de AA. A menudo, oímos que los usuarios de Spark XGBoost se enfrentan a algunos retos comunes, no solo en términos de costos y tiempo de entrenamiento, sino también con la instalación de diferentes paquetes necesarios para ejecutar un paquete de XGBoost escalado o distribuido en un entorno de nube. Incluso si la instalación es correcta, leer un gran conjunto de datos en un entorno distribuido con una partición optimizada puede requerir muchas iteraciones. Los pasos típicos para un entrenamiento de XGBoost incluyen leer datos de almacenamiento, convertirlos a DataFrame y luego pasar a la forma de matriz D de XGBoost para el entrenamiento. Cada uno de esos pasos depende de la potencia de cálculo de la CPU, lo que afecta directamente a la productividad diaria de un científico de datos.
Comprueba tú mismo el ahorro de costos con un notebook de XGBoost de muestra
Para comenzar, puedes usar este
proceso de tres pasos:
- Descarga el conjunto de datos de muestra y los archivos de aplicación de PySpark.
- Crea un clúster de Dataproc con una acción de inicialización.
- Ejecuta una aplicación de notebook de muestra como se explica en los clústeres de comparativas.
Antes de iniciar un clúster de Dataproc, descarga el
conjunto de datos de hipotecas y el
notebook de PySpark XGBoost que ilustra la comparativa que se muestra a continuación. La acción de inicialización facilitará el proceso de instalación para el entrenamiento de XGBoost acelerado por la GPU tanto en un solo nodo como en varios.
El paso de inicialización tiene dos secuencias de comandos separadas. Primero, el objeto
script.sh de inicialización preinstalará el software de la GPU que incluye los controladores de CUDA, NCCL para el entrenamiento distribuido y GPU primitivas para XGBoost. Después, la
secuencia de comandos de rapids.sh instalará las bibliotecas Spark RAPIDS y Spark XGBoost en un clúster de Dataproc. Esos pasos te garantizarán un clúster de Dataproc listo para experimentar con un notebook de muestra.
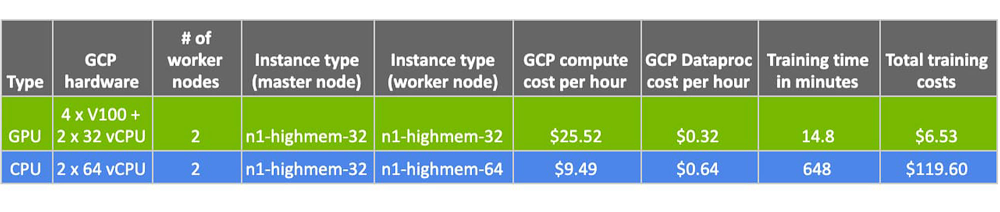
Cómo ahorrar tiempo y reducir costos con GPU
Aquí está el ejemplo que produjo los números que señalamos anteriormente, donde el tiempo de entrenamiento (y, como resultado, los costos) se reducen dramáticamente una vez que se acelera XGBoost: