Nota del Editor: En esta publicación, se muestran proyectos de terceros compilados con AI Platform. En Google I/O, el 18 de mayo de 2021, Google Cloud anunció Vertex AI, una IU unificada para todo el flujo de trabajo de AA, que incluye funcionalidades equivalentes de AI Platform y operaciones de aprendizaje automático nuevas. La mayoría de los códigos de muestra y materiales en esta publicación también serán aplicables a los productos de Vertex AI.
¿Conoces a los expertos en Google Developers Experts (GDE)? El programa GDE es una red de expertos en tecnología con mucha experiencia, influencers y líderes de pensamiento a quienes les apasiona compartir su conocimiento y experiencias con otros desarrolladores. Entre los muchos GDE especializados en varias tecnologías de Google, los GDE de AA (Aprendizaje Automático) han sido muy activos a nivel global, por los que nos gustaría compartir algunas de las grandes demostraciones, muestras y publicaciones de blogs que estos GDE de AA han publicado recientemente para aprender tecnologías de la IA de Cloud. Si te interesa convertirte en un GDE de AA, ve a la parte inferior de este artículo para aplicar.
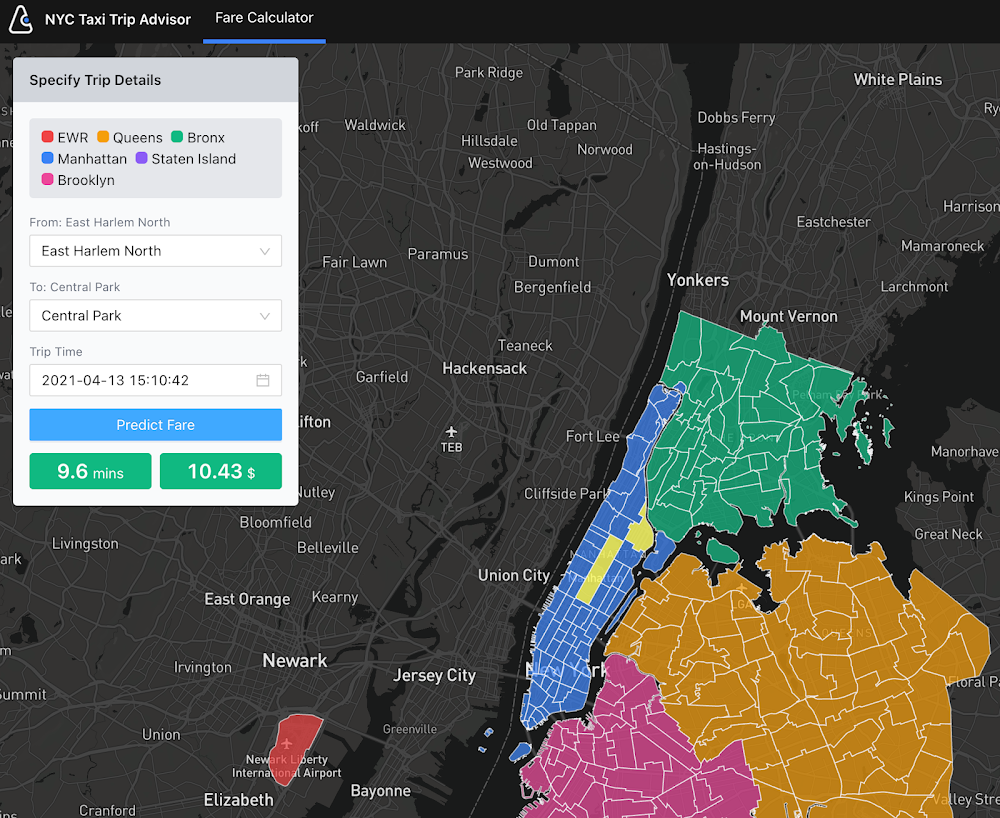
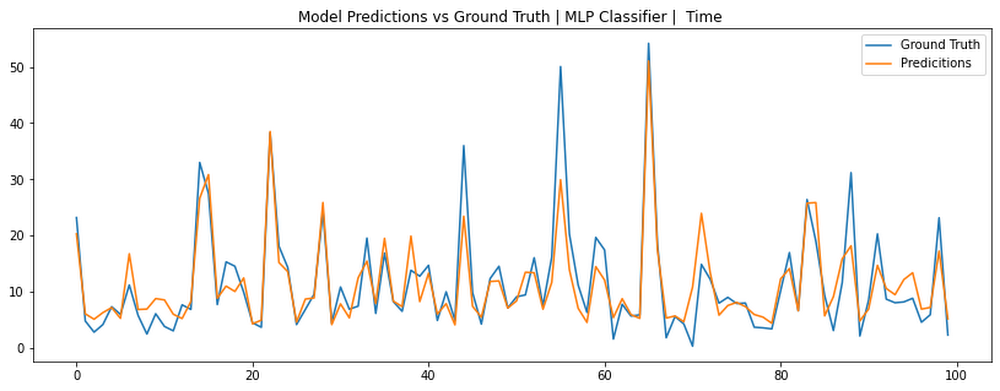
Demostración en vivo: NYC Taxi Trip Advisor
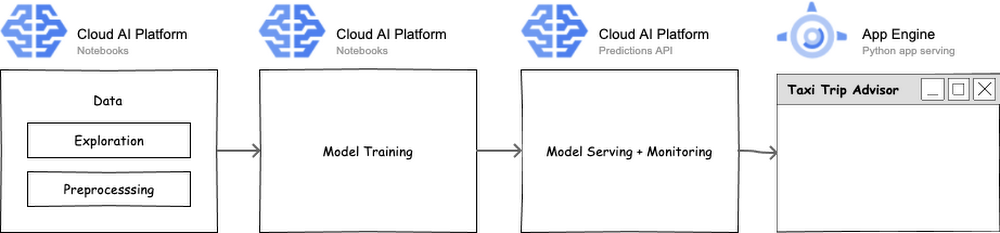
En las Notebooks publicadas en el repositorio de GitHub, Victor explica cómo diseñó la demostración con las Notebooks de Vertex AI, Prediction y App Engine, que incluyen el proceso de descarga de los datos de entrenamiento, el procesamiento previo, el entrenamiento de modelos de AA (Bosque aleatorio y MLP) con scikit-learn, que se implementan en Prediction y se entregan con App Engine. El repositorio se mejorará para ajustar más la experiencia de usuario y los modelos de AA subyacentes (p. ej., el uso de un modelo de predicción bayesiano que admite medidas fundamentadas de incertidumbre).
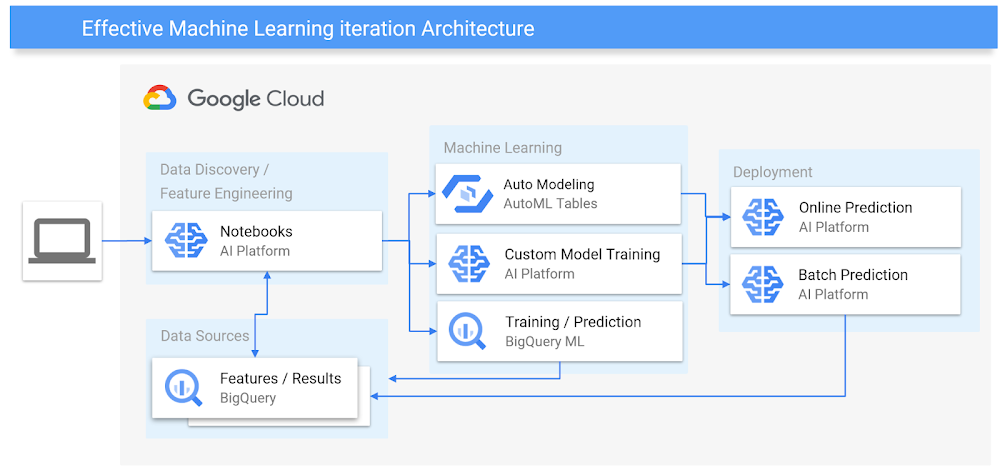
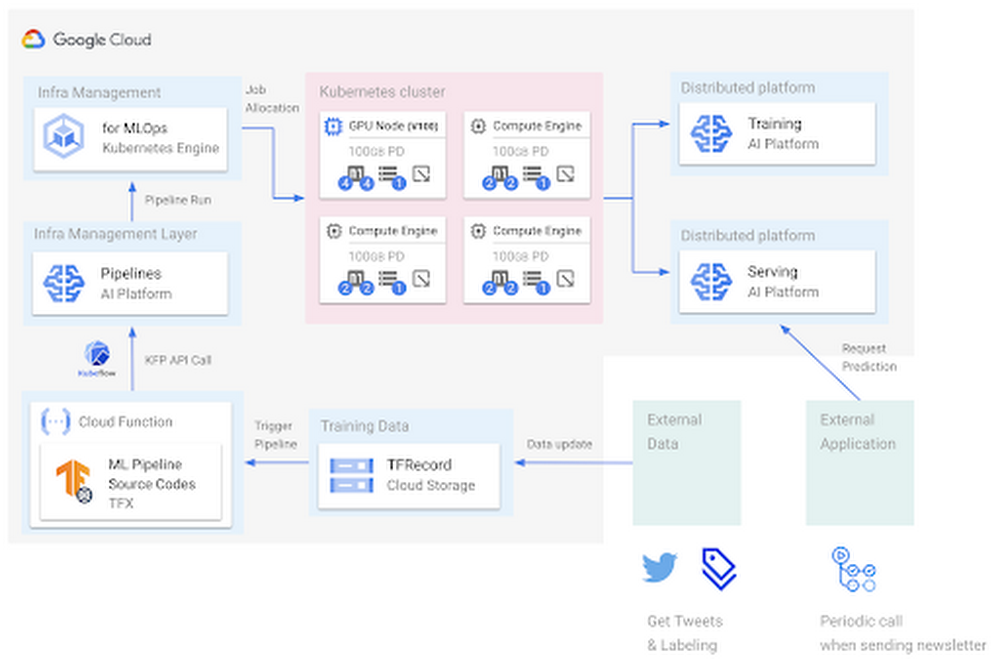
Arquitectura de sistemas
Verificaciones visuales de estado en las predicciones del modelo de MLP.
En la publicación, Minori explica cómo funciona la tecnología de AutoML por medio de la Búsqueda de modelos que Google publicó recientemente. «En el artículo, se menciona que el concepto de búsqueda de modelo utiliza búsqueda de transmisión voraz para varios capacitadores (incluso prueba RNN como LSTM), ajusta la profundidad de las capas y la conexión y, eventualmente, realiza ensambles. Finalmente, crea un modelo escrito en TensorFlow». En realidad, Minori prueba el framework y muestra cómo funciona con un video:
Prueba de Búsqueda de modelos de Minori Matsuda
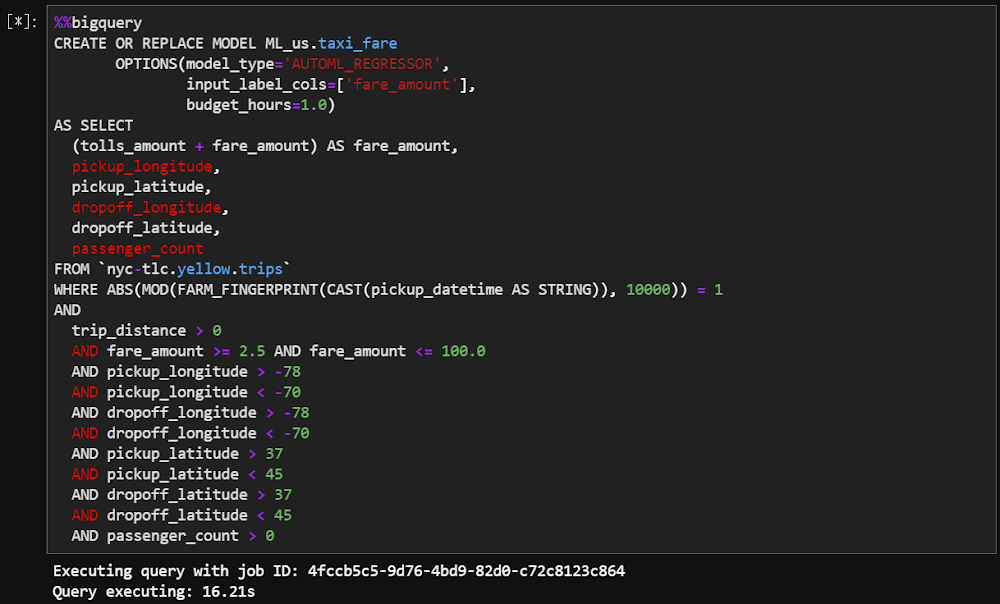
Además, Minori señala que una de las formas más fáciles de crear un modelo de AutoML a partir de un conjunto de datos en BigQuery es usar BigQuery ML en los Notebooks de Vertex AI.
Cómo crear un modelo de AutoML Tables a partir de BigQuery ML en Notebooks de Vertex AI
Este es un gran ejemplo de una solución integrada que puedes redactar con la plataforma potente y servicios de Google Cloud.
Esto no solo es un código de muestra, sino un gran contenido de aprendizaje en línea. Este video incluye introducciones a los siguientes conceptos:
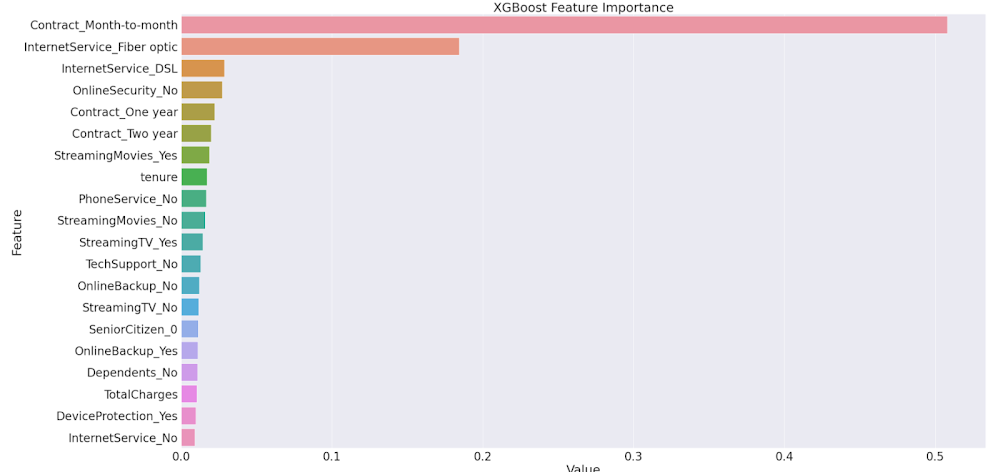
Importancia de los atributos con el modelo XGBoost
Además de AI Platform de Google Cloud y de la predicción de AI Platform, este tutorial en video aborda lo siguiente:
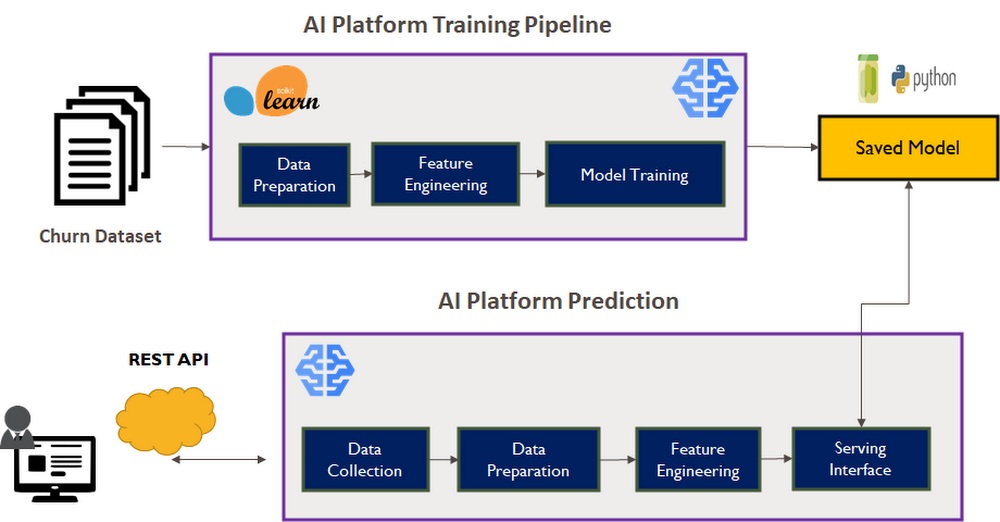
El pasado abril, Sayak Paul publicó el siguiente contenido completo: Distributed Training in TensorFlow with AI Platform & Docker. Comienza de la siguiente manera: «Operar con un entorno de Jupyter Notebook puede ser muy desafiante si estás aprendiendo a usar flujos de trabajo de entrenamiento a gran escala, como es común en el aprendizaje profundo». Utiliza AI Platform y Docker para resolver este problema, al proporcionar un flujo de trabajo de entrenamiento completamente administrado por un servicio seguro y confiable con alta disponibilidad.
Sayak dice: «Mientras desarrollaba este flujo de trabajo, consideré los siguientes aspectos para servicios que usé para desarrollar el flujo de trabajo:»
En esta publicación, explica los procesos de extremo a extremo, desde el diseño de la canalización de datos que toma imágenes de gatos y perros, y convierte a TFRecord almacenado en Cloud Storage.
Canalización de datos con TensorFlow
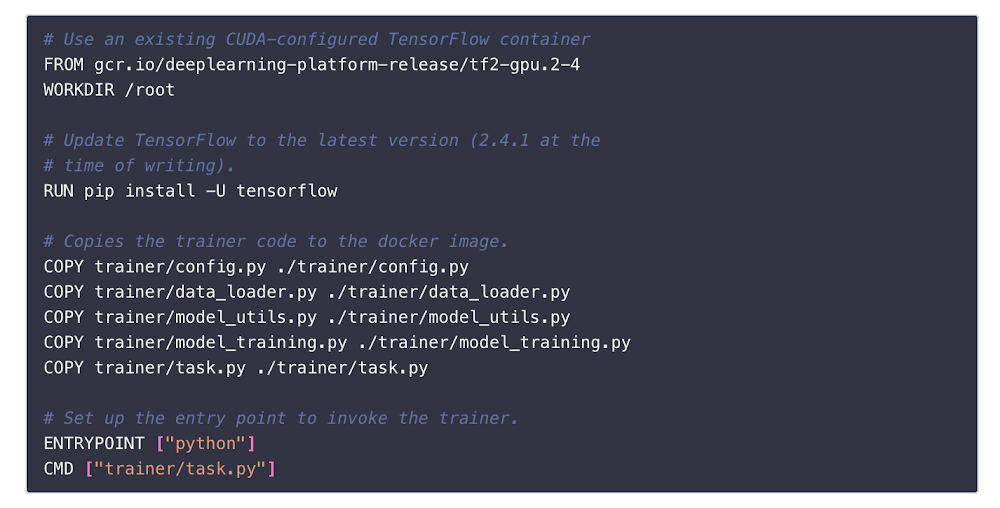
Además, su repositorio publicado contiene todo el código necesario para implementar el flujo de trabajo, con documentación enriquecida que explica cómo se organizan y empaquetan estos archivos en un contenedor de D para que se envíen a AI Platform Training.
Dockerfile para el empaquetado de contenedores
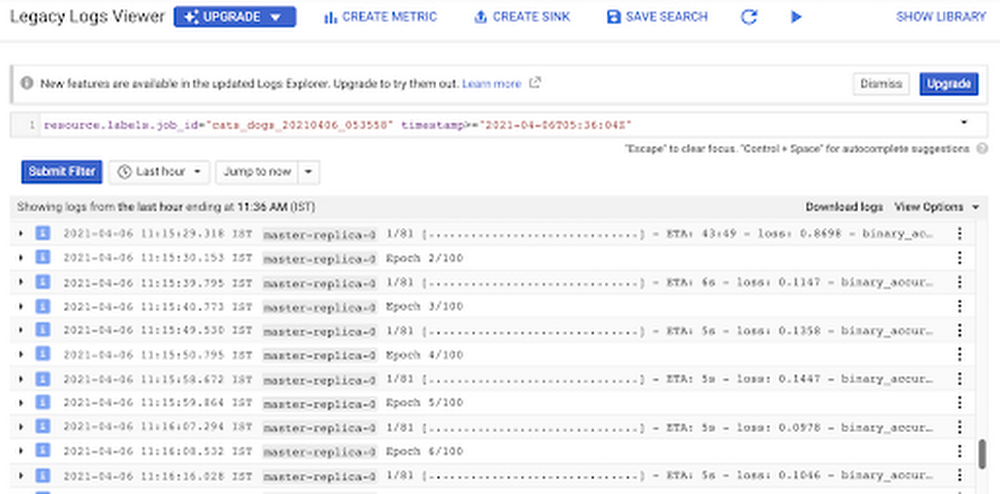
Registros de entrenamiento en Cloud Logging
Si eres un usuario de TensorFlow, la publicación de Sayak podría ser la mejor forma de aprender qué beneficios puedes obtener de AI Platform y cómo iniciar con el código de muestra.
El sistema combina AI Platform Training y Prediction con Google Kubernetes Engine para compilar canalizaciones de operaciones de aprendizaje automático de extremo a extremo para la implementación y entrenamiento continuos siempre que una versión nueva de datos o código para un modelo se integre.
Aunque el proyecto todavía está en desarrollo, es un ejemplo útil de una canalización de aprendizaje automático de extremo a extremo con varios servicios de Google Cloud. Chansung también publicó un gran escrito sobre Operaciones de aprendizaje automático en Google Cloud que también ayuda a entender cómo puedes compilar una producción de canalización de aprendizaje automático con varias herramientas de IA de Cloud.
Si te interesa unirte a una comunidad cercana, visita la página de la comunidad de Google Cloud y busca información relevante sobre reuniones, tutoriales y discusiones.
Si compartes la misma pasión por compartir tu conocimiento y experiencias de la IA de Cloud con otros desarrolladores y te interesa unirte a esta red de GDE de AA, visita el sitio web del programa GDE, visita este video introductorio del programa de GDE de AA y envía un correo electrónico a cloudai-gde@google.com con tu introducción y con la información de actividad relevante.
Artículos relacionados
Google Cloud lanza Vertex AI, una plataforma administrada para experimentar, controlar versiones e implementar modelos de AA en la producción.
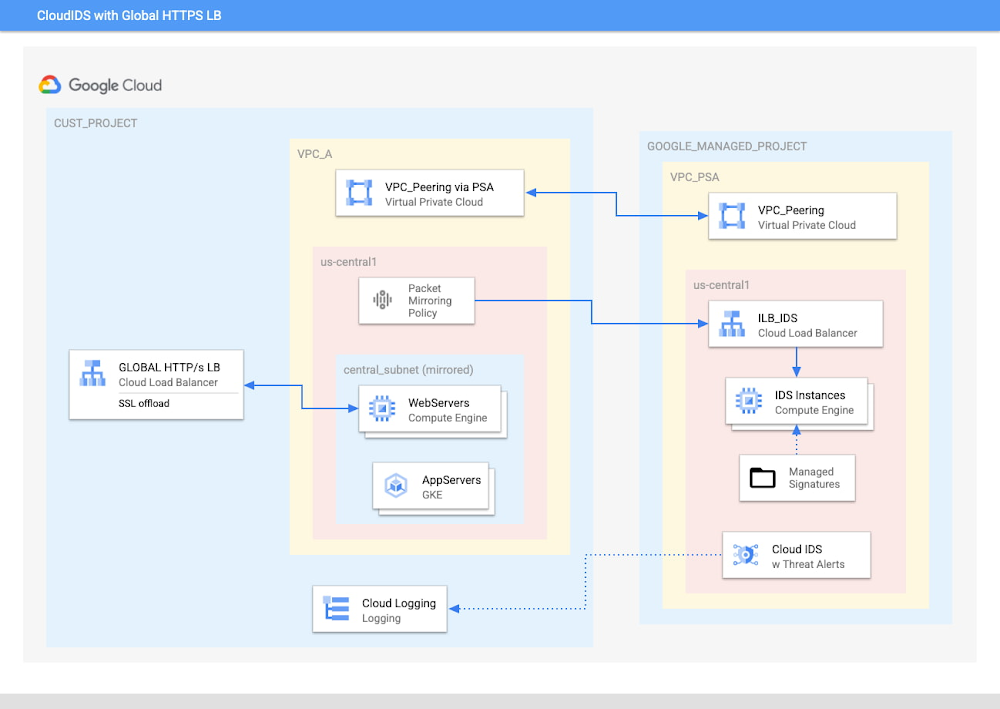
El IDS de Google Cloud, ahora disponible en versión preliminar, es un sistema que ofrece detección de amenazas nativas de la nube, administradas y basadas en red, incluye tecnologías de detección de Palo Alto Networks, líderes en el sector, y proporciona altos niveles de eficacia en seguridad. El IDS de Cloud puede ayudar a los clientes a obtener información valiosa sobre las amenazas basadas en la red y ofrece compatibilidad con los objetivos de cumplimiento específicos del sector que requieren el uso de un sistema de detección de intrusiones. En este blog, analizaremos en detalle el funcionamiento de IDS de Cloud, cómo este sistema logra detectar amenazas basadas en red y de qué manera puedes aprovechar al máximo su implementación.
La implementación de un sistema de detección de intrusiones (IDS) en redes de nube virtuales es obligatoria para muchos clientes como medida clave para garantizar la seguridad de sus redes.
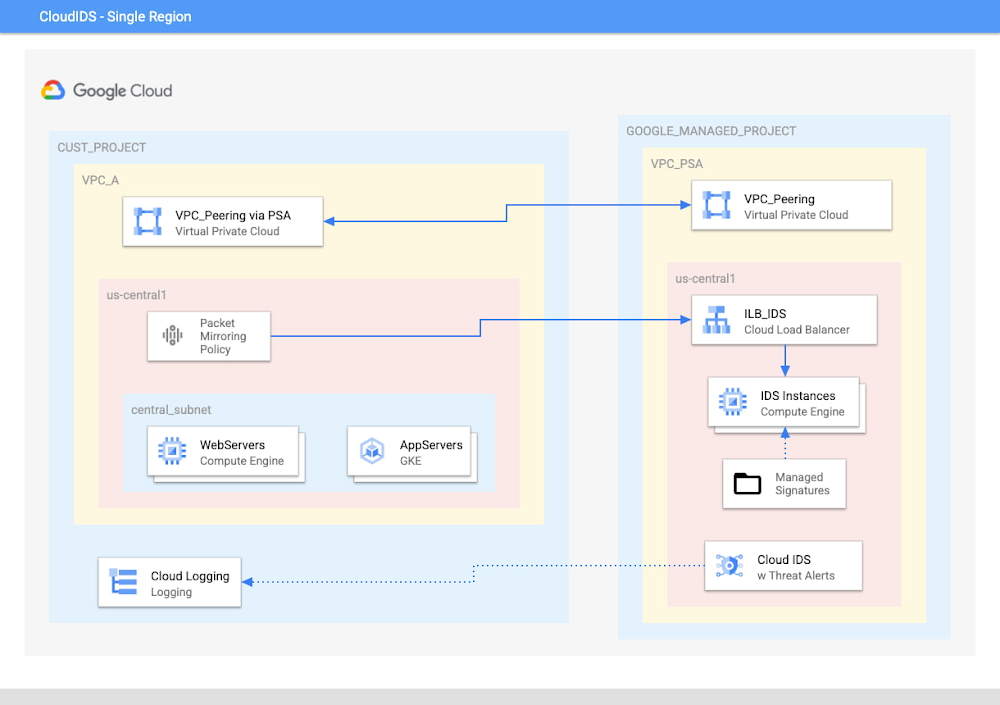
Las prácticas recomendadas y estrategias de diseño que se utilizan para integrar este tipo de sistemas han cambiado y madurado junto con las nuevas tecnologías de redes en la nube. Solucionar problemas, como cuellos de botella en la red y la imposibilidad de inspeccionar el tráfico (este/oeste) dentro de redes VPC, siempre ha sido difícil para los equipos de redes y seguridad. El IDS de Google Cloud se implementa “fuera de la ruta”, lo que evita ambos problemas. El IDS de Cloud utiliza la duplicación de paquetes para copiar y reenviar tráfico de red y el acceso privado a servicios (PSA) para establecer la conexión con un grupo de instancias de IDS nativas de la nube que se encuentran en un proyecto administrado por Google. Esto permite integrar IDS de Cloud sin problemas en una red de Google Cloud Platform (GCP) sin que sea necesario cambiar el diseño de VPC.
A fin de proporcionar visibilidad para las amenazas e intrusiones detectadas por las instancias de IDS, este redirecciona registros de amenazas y alertas de seguridad a Cloud Logging y a la interfaz de usuario de IDS de Cloud en el proyecto del cliente. Todo esto se realiza en un nivel más profundo, de modo que es sencillo implementar y administrar IDS de Cloud. A continuación, presentamos algunos detalles que debes conocer y considerar cuando implementes IDS de Cloud:
Para comenzar, se crea un extremo de IDS de Cloud (un colector de flujos de conexión) que, en segundo plano, implementa tres máquinas virtuales Palo Alto serie VM con firewall, que se encuentran en un proyecto administrado en Google Cloud.
Durante el proceso de creación del extremo de IDS, se deben especificar la zona y la VPC que se analizarán. Una instancia específica de IDS de Cloud puede inspeccionar el tráfico dentro de una región de una VPC.
El IDS de Cloud aplica semanalmente actualizaciones de Palo Alto Networks y las envía a los extremos existentes de IDS.
Durante la creación del extremo, deberás seleccionar un nivel mínimo de gravedad de alerta, de crítico (menos detallado) a informativo (más detallado).
Para redireccionar tráfico al IDS, deberás crear y adjuntar en el extremo una política de duplicación de paquetes.
Cuando crees la política de duplicación de paquetes para adjuntar en IDS de Cloud, tendrás tres opciones para seleccionar las fuentes duplicadas: subredes, etiquetas e instancias individuales.
Subredes: Son útiles cuando se debe analizar cada instancia de una subred. Una política puede contener hasta 5 subredes.
Etiquetas: Son útiles cuando se deben analizar grupos de instancias de una subred o varias. Una política puede contener hasta 5 etiquetas.
Instancias individuales: Utilízalas solo cuando se deban analizar instancias muy específicas. Se permiten 50 instancias por política.
Ahora que te familiarizaste con algunas de las características y los pasos que se deben seguir para crear un IDS de Cloud, veamos algunos puntos claves que te pueden ayudar a aprovechar al máximo la implementación.
Dentro de una política de duplicación de paquetes, hay una opción para filtrar el tráfico. Es importante comprender que un filtro basado en IP interpreta que el rango de direcciones especificado es la subred remota. Es decir, para el tráfico de entrada, el rango de direcciones del filtro sería la red de origen, mientras que para el tráfico de salida, sería la de destino. No uses filtros basados en IP en tus políticas de duplicación de paquetes si no se conoce la red remota, como en el caso del tráfico general basado en Internet. Si los usas, recuerda que puedes evitar que la política de duplicación de paquetes envíe tráfico al IDS, lo que aumenta las oportunidades de que se generen falsos negativos. Además, si vas a usar filtros, asegúrate de recordar el orden de los filtros para la duplicación de paquetes. Si configuras incorrectamente la estrategia de filtrado, puedes duplicar el tráfico y enviarlo fuera de tu IDS de Cloud. Por último, debes capturar siempre el tráfico bidireccional en la opción Dirección del tráfico.
No obstante, en algunos casos de uso los filtros pueden ser bastante útiles. Por ejemplo, si deseas tener diferentes niveles de gravedad de alerta para redes remotas de confianza y no confiables. En este caso, puedes crear dos extremos de IDS con las mismas fuentes duplicadas, pero diferentes filtros y “Gravedad mínima de alerta”. Esta configuración redirecciona el tráfico de red remota más confiable al extremo de IDS que tiene un nivel de gravedad de alerta más moderado, mientras que el tráfico general de Internet se envía al extremo de IDS que tiene una alerta más detallada.
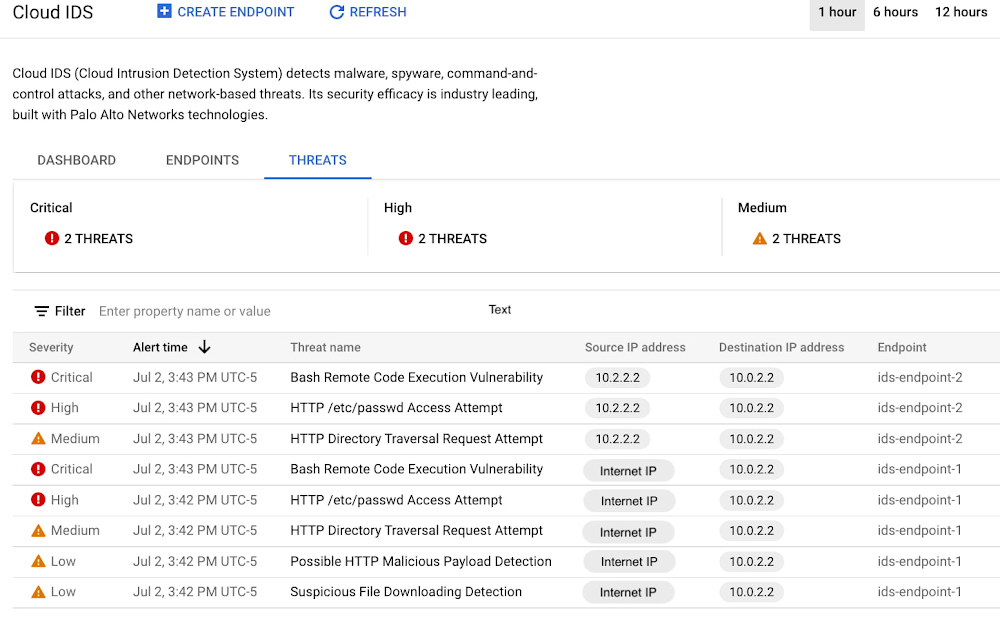
En este ejemplo, ids-endpoint2 analiza el tráfico proveniente de la red de confianza 10.2.0.0/16 y la alerta tiene un nivel de gravedad “Medio” (o superior). Sin embargo, ids-endpoint1 duplica el tráfico no confiable proveniente de Internet y la alerta de amenazas está en nivel “Informativo” (o superior). Ten en cuenta que, en la siguiente captura de pantalla, en “Internet IP” se indicará la dirección de origen como se muestra en la VM duplicada.
El IDS de Cloud ofrece flexibilidad para adjuntar políticas de duplicación de paquetes. Se pueden adjuntar varias políticas de duplicación de paquetes en el mismo extremo de IDS. Por ejemplo, se pueden adjuntar a “ids-enpoint-1” una política de duplicación de paquetes que duplica tráfico para instancias con la etiqueta “app” y una segunda política que captura tráfico para instancias con la etiqueta “app2”. Como alternativa, se puede usar una sola política que capture tráfico para ambas etiquetas de red. Debido a que hoy una política solo puede tener hasta 5 etiquetas, cuando necesites agregar una sexta etiqueta deberás adjuntar una segunda política al extremo de IDS.
Una vez que se adjunta una política, se puede editar al igual que cualquier otra política de duplicación de paquetes. Para quitar la política del extremo, solo debes borrarla, ya que se puede recrear. Por el momento, no hay una opción para “desadjuntar”.
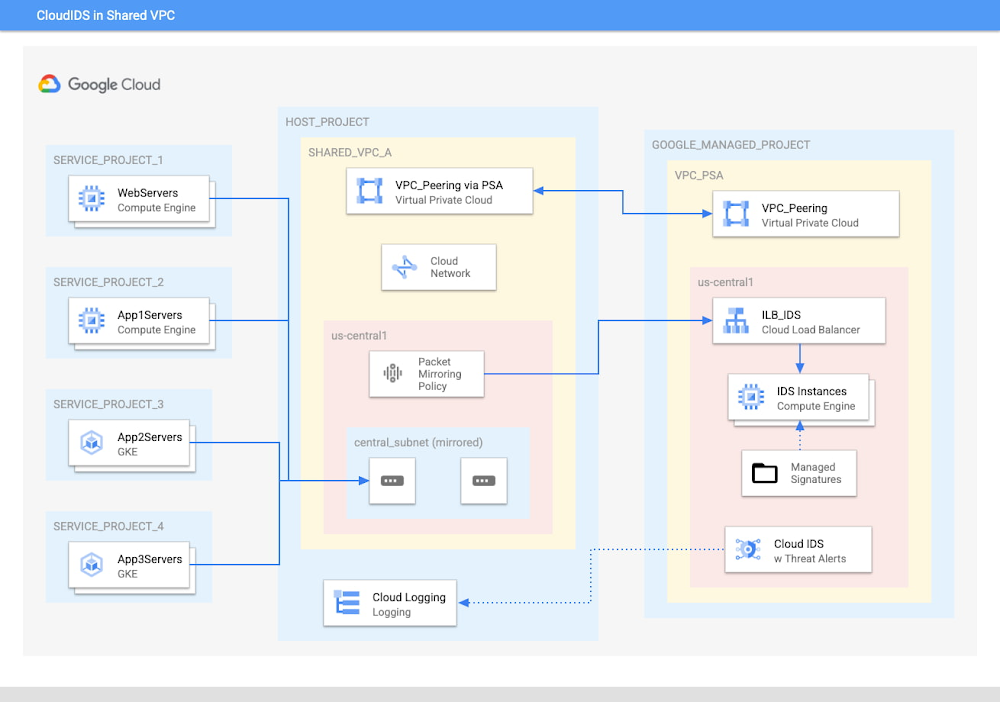
Si tu organización tiene un equipo centralizado de redes y seguridad que trabaja con varios proyectos y se requiere cobertura de IDS para varios proyectos, considera usar una VPC compartida. En este caso, un solo IDS de Cloud puede admitir varios proyectos, ya que estos últimos comparten recursos de red, incluido IDS de Cloud. Se debe crear el extremo de IDS en el proyecto host, donde se encuentra la VPC compartida. En una VPC compartida, IDS de Cloud admite los mismos tres tipos de fuentes duplicadas que en una VPC convencional, incluidas las instancias individuales de los proyectos de servicio.
IDS de Cloud no solo inspecciona el encabezado de IP, sino también la carga útil. Si la carga útil está encriptada, como en el caso del tráfico de HTTPS/TLS/SSL, considera disponer la aplicación detrás de un balanceador de cargas interno L7 (ILB) o un balanceador de cargas externo de HTTP(S). Cuando se usan estos tipos de balanceadores de cargas, se puede realizar la desencriptación de SSL en una capa superior a las instancias duplicadas. De esta manera, IDS de Cloud puede ver el tráfico desencriptado de SSL para inspeccionar y detectar intrusiones y amenazas. Si deseas obtener más información sobre la encriptación de Google Front Ends a los backends del balanceador de cargas, consulta este documento.
Puedes enviar registros de IDS de Cloud de Cloud Logging a herramientas de terceros (p. ej., sistemas Security Information and Event Management [SIEM] y Security Orchestration Automation and Response [SOAR]) para realizar un análisis más detallado y determinar las medidas de mitigación necesarias, según las instrucciones de los equipos de operaciones de seguridad. Se pueden configurar sistemas SIEM y SOAR de terceros para aplicar guías que bloqueen automáticamente la dirección IP de un atacante según la información transferida desde IDS de Cloud. Si vas a utilizar un enfoque automatizado o manual, ten cuidado al bloquear las IP de origen registradas para destinos ubicados detrás de balanceadores de cargas externos o internos basados en proxy. Estos balanceadores de cargas reemplazan la dirección de origen verdadera por una dirección de proxy y, si se rechaza una dirección que se considera atacante, se puede bloquear también el tráfico legítimo. Considera usar Cloud Armor para este nivel de seguridad. Las funciones de control de acceso basadas en firewall de aplicación web (WAF) y capa 4 de Cloud Armor se ejecutan antes de la NAT de origen del balanceador de cargas de Cloud, lo que forma una excelente combinación en un paquete de seguridad.
Debido a que IDS de Cloud es nativo de la nube y se integra con Google Cloud, su implementación es sencilla, proporciona un alto rendimiento y está listo para usar en solo unos clics. Agregar IDS de Cloud a tu VPC existente es fácil y prácticamente no requiere rediseño de la red porque se implementa “fuera de la ruta”. Se puede implementar por completo y ejecutar rápidamente, y enseguida comenzará a generar alertas. Además, puede satisfacer los requisitos de cumplimiento asociados con el uso de un sistema de detección de intrusiones.
Para comenzar a usar IDS de Cloud, mira este video y, si quieres registrarte para obtener acceso a esta vista previa, visita nuestra página web.
Artículo relacionado
IDS (sistema de detección de intrusiones) de Cloud ayuda a detectar software malicioso, software espía y ataques de comando y control
Con el aumento de reclamos por desempleo que alcanzaron cifras récord durante el año pasado, las agencias estatales y locales en Estados Unidos se enfrentaron al desafío de procesar una cantidad de reclamos sin precedentes por semana. La infraestructura digital con la que cuentan la mayoría de las agencias no puede controlar este volumen, lo que provoca tiempos de espera mayores y que las personas malintencionadas se aprovechen de los sistemas vulnerables. El Inspector General del Departamento de Trabajo estima que 63 mil millones de dólares en reclamos distribuidos son un pago indebido o un fraude.
Además, la validación de reclamos exige un intercambio seguro de datos con otras agencias a fin de verificar las identidades y los documentos. Los líderes gubernamentales necesitan una manera que les permitan a los tribunales que presiden las causas desestimar, con rapidez y determinación, los reclamos atrasados, integrar los sistemas existentes y segmentar los reclamos legítimos de los potencialmente fraudulentos; todo dentro de los presupuestos gubernamentales limitados, de manera segura y a gran escala.
Implementación de una solución para detectar fraudes con Google Cloud
Los estados recibieron presión para eximir la responsabilidad por pagos y, al mismo tiempo, filtrar los reclamos que podrían ser fraudulentos. SpringML y Google Cloud desarrollaron un framework para brindar a los tribunales un proceso de verificación confiable que filtra de manera rápida los reclamos potencialmente fraudulentos, a la vez que procesa los restantes, de modo que los beneficios lleguen a los ciudadanos de forma oportuna. SpringML y Google Cloud aplicaron modelos de aprendizaje automático con tecnología de IA para detectar patrones anómalos en grandes conjuntos de datos. Con las herramientas de Google Cloud, SpringML implementó una solución para agilizar los flujos de trabajo, mejorar la eficiencia, automatizar los procesos e identificar reclamos potencialmente fraudulentos.
SpringML recurrió una variedad de productos de Google Cloud a fin de ofrecer una solución para detectar fraudes, por ejemplo:
Implementar el aprendizaje automático para detectar pagos indebidos permite que las agencias clasifiquen los reclamos como "fraude" o "no fraude", según la cantidad de marcas, así como priorizar los más urgentes. El uso de agentes virtuales inteligentes para administrar las preguntas frecuentes permitió que los agentes humanos pudieran concentrar su tiempo en casos más complejos.
Incluso una vez que la pandemia quede en el pasado, las personas malintencionadas intentarán aprovecharse de los sistemas heredados o sobrecargados. Identificamos algunas prácticas recomendadas para las agencias que administran una cantidad de casos enorme y buscan mejorar las estadísticas de pagos indebidos:
Con las herramientas de Google Cloud, podemos actualizar la infraestructura digital, así como también incorporar las prácticas recomendadas de aprendizaje automático para permitir que las organizaciones procesen, de manera eficiente, grandes cantidades de reclamos y puedan identificar los que presentan más probabilidades de ser fraudulentos. SpringML ofrece servicios de implementación y consultoría, y soluciones de estadísticas específicas de la industria que brindan valor empresarial de alto impacto para acelerar la transformación digital basada en datos. Para obtener más información sobre cómo detectar fraudes y mejorar las estadísticas de pagos indebidos, mira nuestro seminario web.
Hace unos meses, escribimos sobre cómo el primer paso para implementar ingeniería de confiabilidad de sitios (SRE) en una organización consiste en la adopción del liderazgo. Supongamos que ya avanzaste y completaste el primer paso. ¿Qué sigue? ¿Cuáles son los pasos concretos que puedes realizar para progresar con la SRE? En esta entrada de blog, analizaremos lo que puedes hacer como líder de TI para acelerar la implementación de la SRE dentro de tu equipo.
Como dice el refrán: "Roma no se construyó en un día", pero tienes que comenzar en algún lugar. Cuando se trata de implementar los principios de la SRE, el enfoque que resultó efectivo para mí (y mi equipo) es comenzar con una prueba de concepto, aprender de nuestros errores e iterar.
Se deben tener en cuenta muchos factores cuando se elige una aplicación o un equipo específicos para la prueba de concepto de la SRE. Sin embargo, la mayor parte del tiempo se trata de una decisión estratégica para la organización, lo que no se evaluará en este artículo. Como posibles escenarios, se puede mencionar un equipo que cambia de operaciones tradicionales o DevOps a SRE, o la necesidad de aumentar la confiabilidad de un producto esencial para la empresa. No importa el motivo, es esencial elegir una aplicación con las siguientes características:
Es fundamental para la empresa. A tus clientes les debe importar mucho el tiempo de actividad y la confiabilidad.
Está actualmente en desarrollo. Elige una aplicación en la que la empresa invierta recursos de manera activa.
En un mundo ideal, la aplicación brinda datos y métricas sobre su comportamiento.
Por el contrario, deberías evitar el software patentado. Si no fuiste tú quien compiló la aplicación, esta no es una buena candidata para la SRE. Es importante que puedas tomar decisiones estratégicas sobre la aplicación y realizar cambios de ingeniería en ella, según sea necesario.
Sugerencia de un profesional: En general, si tienes cargas de trabajo locales y en la nube, trata de comenzar con la app basada en la nube. Si tus ingenieros provienen de un entorno de operaciones tradicionales, cambiar y alejar su manera de pensar de las métricas de infraestructura y los "equipos físicos" será más sencillo para una app basada en la nube, ya que la infraestructura administrada convierte a los profesionales en usuarios y los obliga a consumirla como desarrolladores (API, infraestructura como código, etc.).
Recuerda: Establece metas realistas. Si desalientas a tu equipo con expectativas difíciles de cumplir desde el principio, se producirá un efecto negativo en la iniciativa.
Para implementar los principios de la SRE, es necesario fomentar una cultura de aprendizaje y, en ese sentido, la habilitación del equipo implica capacitarlo (en cuanto al conocimiento), así como otorgarle poder.
Crear un programa de capacitación es un tema en sí mismo, pero es importante pensar en una estrategia de habilitación en una etapa inicial. Particularmente, en organizaciones de gran tamaño, debes abordar temas como el perfeccionamiento de las habilidades internas, la contratación y el escalamiento del equipo, así como la incorporación y la creación de una comunidad de aprendizaje.
Tu estrategia de habilitación también debe adaptarse a los empleados de diferentes niveles y con diferentes funciones. Por ejemplo, la capacitación de los líderes de mayor jerarquía será muy diferente a la capacitación de los profesionales. La capacitación de los empleados en posiciones de liderazgo debería ser suficiente para que estos obtengan aceptación y puedan tomar decisiones organizativas. Con el fin de impulsar el cambio en toda la organización, es posible que se requiera capacitación adicional para los líderes sobre conceptos y prácticas culturales.
Cuando se trata de liderazgo en ingeniería y administración intermedia (gerentes que supervisan gerentes), la capacitación debe ser una combinación de conceptos culturales de alto nivel, de modo que se fomente la cultura necesaria, y prácticas técnicas de SRE lo suficientemente profundas para comprender la priorización, la asignación de recursos, la creación de procesos y las necesidades futuras.
Cuando se trata de profesionales, lo ideal es que toda la organización esté alineada desde una perspectiva del conocimiento y de la cultura. Sin embargo, como mencioné anteriormente, es mejor comenzar de a poco, con un solo equipo.
El punto de partida para esos equipos debe ser comprender la confiabilidad y los conceptos clave, como ANS, SLO, SLI y los porcentajes de error aceptables. Estos conceptos son importantes porque la SRE se centra en la experiencia del cliente. Medir si los sistemas cumplen con las expectativas del cliente exige un cambio de mentalidad y puede llevar tiempo.
Después de que identifiques tu primera aplicación o el equipo que se ocupará de ella, deberás determinar los procesos del usuario de la app (es decir, el conjunto de interacciones que un usuario tiene con un servicio para lograr un objetivo único; por ejemplo, un solo clic o una canalización de varios pasos) y clasificarlos según el impacto empresarial que tienen. Los procesos más importantes se denominan recorridos críticos del usuario (CUJ) y, en estos, debes comenzar a redactar acuerdos de SLO/SLI.
Sugerencia de un profesional: Existen algunas prácticas técnicas generales que te pueden permitir adoptar la SRE con mayor rapidez. Por ejemplo, usar menos repositorios en lugar de más te puede ayudar a reducir los entornos aislados dentro de la organización y utilizar mejor los recursos.
Asimismo, priorizar los procesos automáticos y los sistemas con reparación automática puede beneficiar la confiabilidad, pero también la satisfacción del equipo, lo que ayuda a que la organización conserve el talento.
Nota final: De manera similar a la forma en que tomas decisiones con respecto a la arquitectura, la tecnología, las soluciones y las herramientas de implementación que elijas deben permitirte llevar a la práctica tus objetivos, en lugar de impedírtelo.
Después de establecer estas prácticas de SRE con uno o varios equipos, el siguiente paso es pensar en construir una comunidad de SRE y procesos formalizados en toda la organización. En algunas organizaciones, puedes realizar este paso de manera simultánea con el final del paso 2, y en otras, solo después de completar algunas implementaciones de manera correcta.
En esta fase, es probable que desees ocuparte de la comunidad, la cultura, la capacitación y los procesos. Deberás abordarlos todos, en especial, porque están entrelazados. Sin embargo, el área que priorices dependerá de tu organización.
Construir una comunidad de SRE en la organización es importante desde una perspectiva de aprendizaje, pero también es fundamental para establecer una base de conocimientos sobre prácticas recomendadas, capacitar a expertos en la materia, permitir la implementación de mecanismos de seguridad necesarios y alinear los procesos.
Construir una comunidad va de la mano con fomentar una cultura empoderada y capacitar a los equipos. La idea es que los primeros usuarios sean embajadores de la SRE que compartan sus aprendizajes y capaciten a otros equipos de la organización.
También es útil identificar embajadores o defensores potenciales en equipos de desarrollo individual que demuestran entusiasmo por la SRE y ayudarán con la adopción de estas prácticas.
También es fundamental diseñar capacitaciones que se puedan repetir para cada función práctica, incluidas las sesiones de incorporación. La incorporación de miembros nuevos al equipo es un aspecto crucial para capacitar y fomentar una cultura empoderada de SRE. Por lo tanto, es vital que seas consciente de tu proceso de incorporación y te asegures de que el conocimiento no se pierda cuando los miembros del equipo cambien de funciones.
Durante esta fase, también deseas fomentar una cultura en toda la organización que promueva la seguridad psicológica, acepte el fracaso como algo normal y le permita al equipo aprender de los errores. Para ello, los empleados en posición de liderazgo deben moldear la cultura deseada y promover la transparencia.
Por último, contar con procesos estructurados y formalizados puede ayudar a reducir el estrés con respecto a la respuesta ante emergencias, en especial, en el servicio de guardia. Además, los procesos pueden brindar claridad y lograr que los equipos trabajen de manera más colaborativa y efectiva.
Si deseas producir un mayor impacto, comienza priorizando las áreas más difíciles en el ámbito de trabajo de tu equipo. Por ejemplo, quita las alarmas ruidosas a fin de evitar (o abordar) la fatiga por alarmas, automatiza tus procesos de administración de cambios y, por último, involucra solo a las personas necesarias con el objeto de ahorrar el ancho de banda que utiliza el equipo. Los miembros del equipo no deben trabajar en proyectos de ingeniería de software mientras administran incidentes durante el servicio de guardia, y viceversa. Asegúrate de que cuenten con suficiente ancho de banda para realizar ambas tareas por separado. De manera similar a otras áreas, querrás utilizar datos para impulsar tus decisiones. Por lo tanto, debes identificar en qué sectores pasan más tiempo tus equipos y durante cuánto tiempo.
Si la recopilación de este tipo de datos te resulta un desafío, ya sea cuantitativo o cualitativo, un buen punto de partida suelen ser tus procesos de respuesta ante emergencias. Estos producen un impacto directo en la empresa, en especial, en lo que respecta al proceso de escalamiento, la administración de incidentes y las políticas relacionadas.
Sugerencia de un profesional: Todas las prácticas anteriores contribuyen a reducir los entornos asilados y alinear los objetivos en toda la organización, que también deben incluir a tus proveedores y socios de ingeniería. Para ello, asegúrate de que tus contratos con ellos también reflejen estos objetivos.
Comenzar el recorrido de la SRE puede llevar tiempo, incluso si solo lo implementas para un equipo. Dos victorias rápidas con las que puedes comenzar, y que producirán un efecto positivo, son la recopilación de datos y el análisis retrospectivo libre de responsabilidad.
En la SRE, intentamos basarnos en los datos en la mayor medida posible, por lo que, en tu organización, es fundamental que fomentes una cultura de medición. Cuando se prioriza la recopilación de datos, lo ideal es buscar datos que representen la experiencia del cliente. La recopilación de estos datos te permitirá identificar tus brechas y priorizar según las necesidades de la empresa y, en consecuencia, las expectativas de tus clientes.
Otra medida que puedes tomar es generar o mejorar los análisis retrospectivos, que representan una manera fundamental de aprender de los errores y fomentar una cultura sólida de SRE. Según nuestra experiencia, incluso las organizaciones que sí generan análisis retrospectivos, pueden beneficiarse mucho más con algunas leves mejoras. Es importante recordar que los análisis retrospectivos deben deshacerse de la responsabilidad para que el equipo se sienta seguro de compartir y aprender de los errores. Además, para lograr que el futuro sea mejor que el presente (es decir, no repetir los mismos errores), es importante que los análisis retrospectivos incluyan elementos de acción y se asignen a un propietario.
Crear un repositorio compartido para los análisis retrospectivos puede generar un impacto inmenso en el equipo: aumenta la transparencia, reduce los entornos aislados y contribuye a la cultura de aprendizaje. También le demuestra al equipo que la organización "practica lo que predica". Esta implementación puede ser tan sencilla como crear una unidad compartida.
Sugerencia de un profesional: Los análisis retrospectivos deberían deshacerse de la responsabilidad y ser prácticos.
Desde luego, no existen dos organizaciones iguales ni tampoco dos equipos iguales de SRE. Sin embargo, si sigues estos pasos, puedes lograr que tu equipo implemente la SRE de manera correcta y rápida. Para obtener más información sobre cómo desarrollar una práctica efectiva de SRE, consulta los siguientes recursos.
Recopilación de recursos públicos sobre la SRE
Paquetes de SRE de servicios profesionales de Google
El proceso para convertirse en un taller exitoso de ingeniería de confiabilidad de sitios comienza mucho antes de que tomes tu primera clase o leas tu primer ma…
Flutter es el kit de herramientas de Google que permite compilar apps atractivas de forma nativa para dispositivos móviles, la Web y computadoras de escritorio a partir de una única base de código. En los últimos años, se convirtió en la primera opción para los desarrolladores que desean crear apps en distintas plataformas. Sin embargo, los diseñadores necesitan una herrramienta visual para crear prototipos y compilar IU en Flutter, en lugar de hacerlo manualmente con el código fuente de Dart. Ingresa a XD a Flutter.
Ya casi pasó un año desde la primera versión preliminar del complemento, y seguimos perfeccionándolo gracias a un conjunto de pequeñas actualizaciones, el gran lanzamiento de la versión 1.0 el verano boreal pasado y ahora la versión 2.0 que coincide con el lanzamiento de Flutter 2.
Su nombre ya lo indica: el complemento XD a Flutter es una herramienta eficaz y fácil de usar con la que puedes convertir tus diseños increíbles de Adobe XD en un código ordenado que funcione con Flutter. Puedes copiar el código de elementos visuales específicos de tus diseños y exportar widgets reutilizables o incluso vistas enteras.
De esta manera, el complemento XD a Flutter te permite ejecutar diseños en casi todos los dispositivos con solo hacer clic en un botón. No hará todo el trabajo por ti, pero te ayudará a empezar.
XD a Flutter fue creado por gskinner de forma conjunta con Adobe y se publicó como un complemento para Adobe XD, por lo que puedes usarlo con cualquier diseño de Adobe XD que estés creando.
La versión inicial de XD a Flutter permitía la transferencia de los distintos elementos visuales de diseño, como gráficos vectoriales, imágenes, texto enriquecido, fondos desenfocados, modos de fusión, sombras y mucho más, pero los resultados a veces eran inflexibles y estáticos.
Si bien era útil para copiar un ícono o estilo de texto, queríamos que hiciera más. XD ayuda a los diseñadores a crear IU dinámicas con herramientas como diseños adaptables, áreas desplazables y cuadrículas. Nuestro objetivo es que el complemento admita todas estas funciones, y con la versión 2.0 logramos varios avances.
XD a Flutter admite las funciones de diseño adaptable de XD, lo que permite "fijar" los elementos que se encuentren dentro del elemento principal y controlar con precisión la forma en la que cambian de tamaño.
En Flutter, lo logras mediante un widget de diseño fijado del paquete de adobe_xd de código abierto que los desarrolladores pueden usar directamente en sus proyectos.
Las "pilas" y los grupos de desplazamiento brindan maneras nuevas de mostrar el contenido en pantalla de forma dinámica en Adobe XD. Con las pilas de XD, puedes distribuir un grupo de elementos en una lista horizontal o vertical, con espaciados diferentes entre ellos. Se asemejan más a los widgets flexibles de Flutter que al widget de pila.
Con los grupos de desplazamiento, como su nombre lo indica, puedes definir un área en el que se desplazará una gran parte del contenido de manera horizontal o vertical dentro de tu diseño.
XD a Flutter v2.0 admite estas funciones y las convierte en widgets comunes de Flutter (Column, Row y SingleChildScrollView). También puedes colocar una pila dentro de un grupo de desplazamiento a fin de crear rápidamente una lista de elementos desplazables.
Otra función nueva son los elementos de fondo, con los que puedes designar un elemento visual como fondo para un grupo. Combínalo con relleno a fin de agregar espacio entre los bordes del fondo y el contenido.
El complemento exportador de Flutter usa un widget de pila para colocar la capa del elemento de fondo detrás del contenido y agregarla a un widget de relleno.
Las funciones de diseño que se describieron antes permiten lograr una IU mucho mas adaptable, lo que complementa la compatibilidad adicional de Flutter 2 con factores de forma, como computadoras de escritorio y la Web.
Asimismo, Flutter 2 ofrece seguridad nula sólida, una función del lenguaje que ayuda a los desarrolladores a detectar problemas de nulabilidad antes de que generen problemas en las apps. XD a Flutter v2.0 incluye la nueva configuración "Export Null Safe Code", que garantiza que el código generado sirva en el futuro.
Ya sea que lo quieras utilizar para copiar el código de un gradiente complicado o exportar widgets con parámetros, totalmente interactivos y adaptables, puedes unirte a los miles de profesionales creativos que ya están usando el complemento XD a Flutter.
Puedes instalarlo seleccionando "Browse Plugins…" desde el menú "Plugin" de Adobe XD y buscar "Flutter" (no lo encontrarás si buscas "XD a Flutter"). También puedes visitar adobe.com/go/xd_to_flutter.
Una vez que lo hayas instalado, abre el panel de XD a Flutter desde el panel de complementos y presiona el vínculo de ayuda para consultar la documentación del complemento.
Flutter 2 representa un avance importante para el framework, ya que se centra en la compilación de apps atractivas que se pueden ejecutar desde casi cualquier dispositivo. En gskinner, nos emociona trabajar con Adobe y Google para que XD a Flutter siga simplificando aún más el proceso de convertir diseños increíbles en un producto funcional.
¡No te pierdas las próximas actualizaciones!
Luego de su paso por Google For Startups Accelerator (GFSA), la empresa mexicana BeepQuest se trazó una nueva y ambiciosa misión — y confía en Google Cloud Platform para lograrla
Antes de Google For Startups Accelerator, BeepQuest ya tenía bastante éxito. Sin inversión externa y creciendo al lado de sus clientes, esta startup mexicana logró construir un portafolio de clientes que incluye a varios gigantes corporativos de Latinoamérica. Los COOs y líderes operativos de las empresas quedan tan felices que BeepStrap puede entrevistarlos en su podcast especializado en Saas.
Pero la compañía, que se especializa en ayudar a las empresas a optimizar procesos de supervisión, auditoría y aseguramiento de calidad, encontró una nueva misión tras su paso por aceleradora: llegar a todas las Pymes de Latinoamérica. “Queremos darle también la oportunidad a clientes más pequeños a que lleguen a los resultados que han obtenido nuestros clientes corporativos”, dice Berny Mohnblatt, CEO y cofundador de la empresa.
“GFSA nos ayudó a darnos cuenta que la solución que tenemos se puede adaptar a cualquier tipo de empresa sin importar su tamaño, y que la oportunidad de BeepQuest en el mercado de las Pymes también es supremamente atractiva”, dice Mohnblatt.
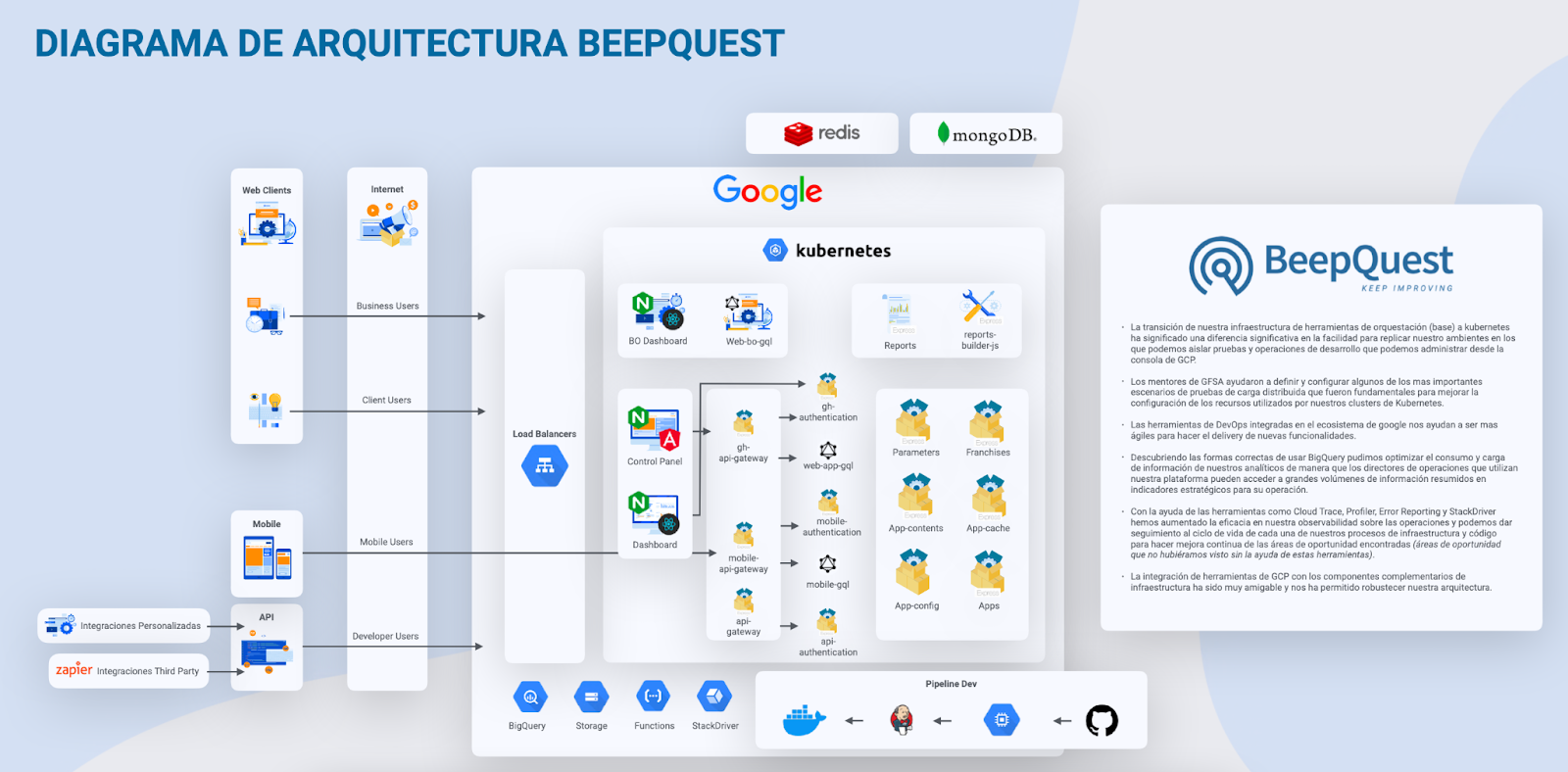
Para cumplir ese reto, BeepQuest requiere de una infraestructura tecnológica y humana robustas y flexibles, que le permitan adaptarse a las necesidades de diferentes industrias y cumplir con el volumen requerido para atender la demanda. Para eso, la empresa confía en Google Cloud Platform, tal como lo ha hecho desde sus comienzos.
“Tanto nuestra estructura operativa como nuestra arquitectura de devops está 100% con Google. Hemos sido clientes desde el principio y hemos especializado a nuestro equipo de desarrollo a ejecutar las mejores prácticas de Kubernetes, y una arquitectura de microservicios orquestados como ninguna otra. La excelente oferta de nube de Google nos ha hecho quedar súper bien con cientos de clientes, nunca nos ha dejado colgados”, dice Mohnblatt.
Diagrama de arquitectura
Además de optimizar su uso de herramientas de Google Cloud, en esta nueva etapa, la compañía aprovechará las habilidades en mercadeo, gestión de equipos y diseño que adquirió en GFSA. Por ejemplo, Mohnblatt dice que la metodología de design sprint que aprendió en el programa les ayudará a escalar la plataforma de manera más asertiva.
Además, Mohnblatt cuenta que la compañía también tomó decisiones de marketing tras terminar su ciclo en GFSA. “Hemos definido una estrategia de marketing a través de SEO, customer funnels, segmentación de mercado, Google Ads y lead magnets que va a encajar perfectamente con nuestras ambiciones de crecimiento”.
Estos aprendizajes y nuevas herramientas apoyarán la próxima etapa de crecimiento de BeepQuest. Con un equipo capaz y experimentado y un producto ganador que les ha permitido crecer 100% con boostrapping a partir de su propia capacidad de ventas, el próximo paso es atraer inversión para poner en práctica todos estos aprendizajes y avanzar en el prometedor camino que encontraron. Como dice Mohnblatt, GFSA “realmente nos ha ayudado a definir un norte con la empresa”.